Elastic search là gì?
Elasticsearch là một hệ thống tìm kiếm và phân tích dữ liệu phân tán, xây dựng trên thư viện Lucene. Nó hoạt động theo mô hình cluster gồm nhiều node, lưu trữ dữ liệu dưới dạng document (tài liệu JSON) trong các index. Mỗi index được chia thành các shard (phân đoạn) để phân phối dữ liệu trên các nút. Mỗi shard chính (primary shard) có thể có một hoặc nhiều bản sao (replica) để dự phòng và tăng khả năng đọc/phục vụ truy vấn.
- Cụm (Cluster): Là tập hợp các nút Elasticsearch hoạt động chung. Ta có thể thêm hoặc bớt nút (servers) vào cụm để mở rộng quy mô, và Elasticsearch sẽ tự động cân bằng dữ liệu và tải truy vấn giữa các nút.
- Nút (Node): Là một tiến trình Elasticsearch chạy trên máy chủ. Mỗi node có thể đảm nhiệm các vai trò khác nhau (như master, data, ingest, v.v.), nhưng chúng cùng tham gia lưu trữ và xử lý dữ liệu của cụm.
- Chỉ mục (Index): Một namespace logic chứa tập hợp các tài liệu có cấu trúc JSON. Mỗi index được chia thành một hoặc nhiều shard vật lý. Ví dụ, index
productscó thể chia thành 5 primary shard, mỗi shard lưu một phần bộ sưu tập sản phẩm. - Shard: Mỗi shard là một bản Lucene index độc lập chứa một phần dữ liệu của index. Vì vậy, một index lớn có thể được phân tán trên nhiều node (mỗi node có thể chứa một số shard). Nhờ vậy, Elasticsearch tăng khả năng song song cho cả việc đánh chỉ mục và truy vấn.
- Replica (Bản sao): Là bản sao của primary shard. Các replica cho phép phục hồi khi một shard chính gặp lỗi và tăng khả năng xử lý truy vấn (đọc) bởi vì có nhiều bản dữ liệu giống nhau trên các node khác nhau. Số replica có thể thay đổi sau khi tạo index mà không gián đoạn hoạt động.
Cơ chế đánh chỉ mục và tìm kiếm
Khi một tài liệu JSON được đưa vào Elasticsearch (đánh chỉ mục), nó sẽ được phân tích (analysis) trước khi lưu. Quá trình phân tích văn bản dùng một analyzer – một gói gồm bộ lọc ký tự, bộ tách từ và các bộ lọc token. Cụ thể:
- Trước hết, bộ tách từ (tokenizer) sẽ nhận luồng ký tự đầu vào và tách thành các token (thường là các từ). Ví dụ, bộ tách theo khoảng trắng (whitespace tokenizer) sẽ chia câu
"Quick brown fox!"thành các token["Quick","brown","fox!"]. Bộ tách cũng ghi nhận vị trí và độ dài của token để hỗ trợ truy vấn phân cụm (phrase queries) sau này. - Sau khi tách từ, bộ lọc token sẽ xử lý các token vừa tạo ra: ví dụ chuyển thành chữ thường, loại bỏ các từ dừng (stop words), áp dụng stemming hoặc thêm từ đồng nghĩa. Ví dụ, bộ lọc
lowercasesẽ chuyển tất cả token sang chữ thường, bộ lọcstopsẽ loại bỏ từ “và”, “the”, v.v. Kết quả là một luồng token cuối cùng đã được chuẩn hóa.
Sau khi phân tích xong, mỗi token sẽ được thêm vào chỉ mục đảo ngược (inverted index). Chỉ mục đảo ngược là cấu trúc dữ liệu cốt lõi cho tìm kiếm toàn văn: nó duy trì danh sách tất cả các từ (token) duy nhất xuất hiện trong các tài liệu, và với mỗi từ lưu danh sách các tài liệu chứa từ đó. Nhờ vậy, khi truy vấn một từ, Elasticsearch chỉ cần tra cứu trực tiếp vào inverted index, thay vì quét từng tài liệu một. Ví dụ, hai câu “the quick fox” và “quick dog fox” sau khi phân tích (loại bỏ stop-word “the”) sẽ lưu inverted index như:
Term Doc1 Doc2 quick X X fox X X dog X
Các tính năng chính
- Full-text search (Tìm kiếm toàn văn): Elasticsearch nổi tiếng với khả năng tìm kiếm văn bản mạnh mẽ. Tốc độ truy vấn cao đến từ inverted index, còn tính linh hoạt và độ chính xác đến từ bộ dò (scoring), các truy vấn phong phú (Query DSL) và khả năng tinh chỉnh phân tích ngôn ngữ. Người dùng có thể sử dụng cú pháp truy vấn JSON cho phép tìm kiếm cụm từ (phrase), boolean, fuzziness, proximity, v.v. Ví dụ, truy vấn tiếng Việt có thể dùng bộ phân tích tiếng Việt (analysis) để tách từ và so khớp chính xác theo ngữ cảnh.
- Distributed Search (Tìm kiếm phân tán): Elasticsearch tự động phân phối dữ liệu và tải truy vấn trên các node trong cụm. Khi một truy vấn được gửi đến cụm, nó sẽ được lan truyền đến các shard tương ứng trên từng node (giai đoạn query), sau đó thu thập và sắp xếp kết quả từ các shard (giai đoạn fetch). Cơ chế này cho phép mở rộng quy mô ngang: thêm node mới sẽ tăng khả năng xử lý truy vấn. Các bản sao (replica) cũng tham gia xử lý truy vấn đọc, giúp cân bằng tải.
- Aggregation (Tập hợp và phân tích số liệu): Elasticsearch hỗ trợ mạnh mẽ các phép tổng hợp (aggregation) để tính toán và nhóm dữ liệu. Thay vì chỉ trả về các tài liệu đơn lẻ, ta có thể yêu cầu Elasticsearch trả về các thông tin phân tích như tổng, trung bình, đếm, biểu đồ tần suất (histogram), phân nhóm (terms bucket), chuỗi (pipeline) trên tập kết quả tìm kiếm. Ví dụ, đếm số sản phẩm theo loại, hoặc tính giá trị trung bình của trường “giá” cho từng danh mục. Việc này rất hữu ích cho báo cáo và trực quan hóa dữ liệu (ví dụ Kibana sử dụng aggregation để vẽ biểu đồ từ dữ liệu Elasticsearch).
- RESTful API: Tất cả các chức năng của Elasticsearch đều được cung cấp qua giao diện RESTful API sử dụng JSON qua HTTP (mặc định cổng 9200). Người dùng và ứng dụng có thể tạo index, thêm sửa xóa tài liệu, tìm kiếm, và quản lý cluster bằng cách gọi các endpoint như
PUT /indexhayGET /index/_searchvới yêu cầu JSON. API này giúp tích hợp dễ dàng với nhiều ngôn ngữ lập trình và công cụ qua các thư viện chính thức hoặc chỉ dùngcurl.
So sánh Elastic Search, MySQL/PostgreSQL và MongoDB
| Đặc điểm | Elasticsearch | MySQL/PostgreSQL | MongoDB |
|---|---|---|---|
| Mô hình dữ liệu | Document store, lưu dữ liệu dưới dạng JSON phân tán. Mỗi document linh hoạt, cho phép lưu cấu trúc phức tạp mà không cần schema cứng nhắc. | Quan hệ (RDBMS) – lưu dữ liệu theo bảng (rows/columns) kèm quan hệ khóa ngoại. Dữ liệu phải theo schema xác định trước (DDL). | Document store (NoSQL) – lưu dữ liệu dưới dạng document (JSON/BSON) không cần schema. Mỗi DB chứa nhiều collection (tương tự bảng). |
| Ngôn ngữ truy vấn | JSON Query DSL hoặc Elasticsearch SQL. Hỗ trợ các truy vấn tìm kiếm toàn văn, boolean, fuzzy, v.v.. | SQL chuẩn: thao tác dựa trên truy vấn quan hệ (SELECT, JOIN, v.v.). | API truy vấn riêng (BSON) và MongoDB Query Language. Có hỗ trợ text index nhưng giới hạn (chưa có tính năng phân tích ngôn ngữ như ES). |
| Tìm kiếm toàn văn (FTS) | Rất mạnh – sử dụng inverted index và hệ số trọng số (scoring) cao cấp. Tối ưu cho truy vấn văn bản, hỗ trợ ngôn ngữ, từ gốc (stemming), tokenization tùy chỉnh. | Thông thường chậm hơn cho văn bản; PostgreSQL có hỗ trợ Full Text Search, MySQL có plugin, nhưng không linh hoạt bằng Elasticsearch. | Có hỗ trợ text index nhưng hiệu suất kém hơn Elasticsearch, thiếu bộ phân tích (tokenizer, stemmer) tinh vi. |
| Giao dịch (Transactions) | Không hỗ trợ giao dịch nhiều tài liệu một cách ACID. Elasticsearch chỉ đảm bảo mỗi thao tác CRUD trên document là bền vững (qua write-ahead log) nhưng không rollback toàn bộ giao tác nếu có lỗi. | Hỗ trợ ACID đầy đủ, các giao dịch SQL với commit/rollback theo chuẩn. | MongoDB hỗ trợ giao dịch ACID giới hạn (phiên bản mới hỗ trợ multi-doc transaction), trước đây chủ yếu là mô hình BASE. |
| Mở rộng quy mô (Scale) | Mở rộng ngang dễ dàng – thêm node mới để tăng sức chứa và xử lý. Tự động chia shard và cân bằng dữ liệu giữa các node. | Thông thường mở rộng dọc (tăng cấu hình máy chủ). Để scale-out, cần dùng các giải pháp phức tạp như sharding ngoài. | Mở rộng ngang tự nhiên – có tính năng sharding và replica. Thiết kế ban đầu để phân tán trên nhiều máy. |
| Công năng và tính năng khác | Tối ưu cho analytics và tìm kiếm; hỗ trợ aggregation phong phú, phân tích log, truy vấn thời gian thực gần (near-real-time). Đi kèm hệ sinh thái ELK (Kibana, Logstash). | Tối ưu cho OLTP, thao tác dữ liệu có cấu trúc, báo cáo quan hệ. Không hỗ trợ sẵn nhiều chức năng tìm kiếm toàn văn hay phân tích thời gian. | Tối ưu cho dữ liệu linh hoạt và cần truy vấn JSON. Không có công cụ phân tích mạnh như ES; chủ yếu dùng để lưu trữ và truy vấn dữ liệu linh hoạt. |
Bài viết khác

Blockchain
Blockchain là gì? Blockchain là một công nghệ sổ cái phân tán (distributed ledger) lưu trữ dữ liệu dưới dạng các khối (blocks) được liên kết với nhau theo chuỗi (chain) bằng các hàm băm mật mã (cryptographic hash). Mỗi khối chứa danh sách các giao dịch, dấu thời gian, và tham chiếu đến khối […]

Computer Graphics
1. Ray Tracing Là một kỹ thuật mô phỏng ánh sáng trong đồ họa máy tính nhằm tạo ra hình ảnh cực kỳ chân thực. Phương pháp này dựa trên việc mô phỏng hành trình của các tia sáng từ mắt người (camera) đi vào không gian 3D, và tính toán cách chúng tương tác […]

Tìm hiểu RabbitMQ
RabbitMQ là gì? RabbitMQ là một message broker, triển khai giao thức AMQP (Advanced Message Queuing Protocol). Nhiệm vụ chính là tiếp nhận, lưu trữ tạm thời và chuyể n tiếp message giữa các Producer (gửi) và Consumer (nhận). Mục đích sử dụng RabbitMQ: phân tách các thành phần khác nhau trong hệ thống, xử […]

So sánh GORM vs go-pg vs Bun
Cộng đồng GORM Là ORM phổ biến nhất trong cộng đồng Go. Có nhiều tài liệu, ví dụ, StackOverflow câu trả lời, và nhiều package hỗ trợ mở rộng. Nhiều developer đã từng dùng Gorm. go-pg Từng rất phổ biến khi chỉ dùng PostgreSQL, nhưng đang bị Bun thay thế dần. Ít được duy trì […]
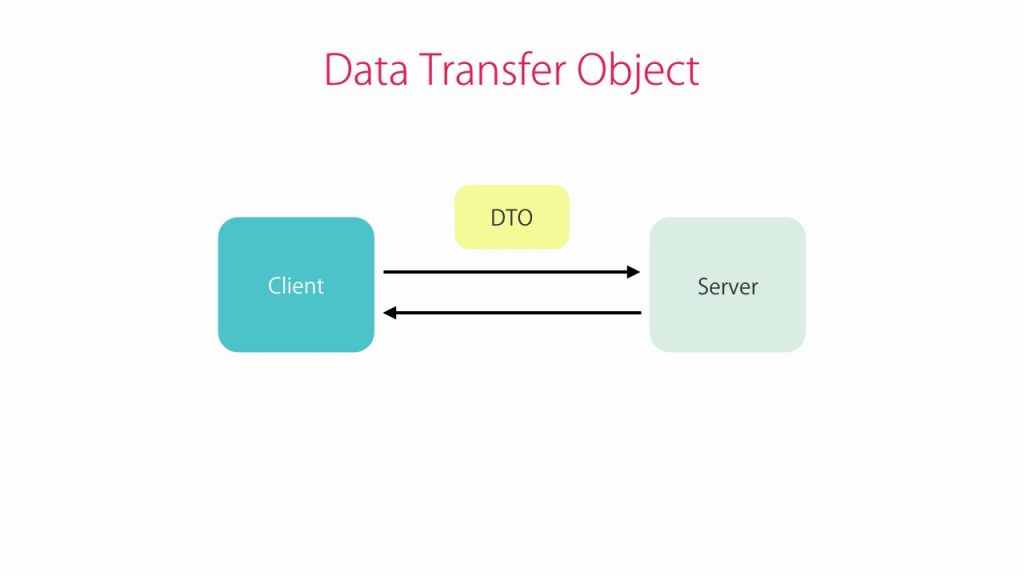
Sử dụng Request/Response trong ứng dụng RESTful mô hình MVC
DTO là gì? DTO (Data Transfer Object) là một object trung gian dùng để truyền dữ liệu giữa client – server hoặc giữa các service trong ứng dụng web/API theo kiến trúc RESTful API. DTO chỉ chứa các thông tin cần thiết mà client hoặc service khác cần (ví dụ: Login Form chỉ cần thông […]

Docker
Docker là gì? Docker là một nền tảng mã nguồn mở cho phép bạn đóng gói, phân phối và chạy ứng dụng bên trong các “container” – những môi trường ảo nhẹ, cô lập nhưng vẫn chia sẻ nhân hệ điều hành của máy chủ. Khái niệm then chốt ở đây là “containerization”: thay vì […]
 Khoá học lập trình game con rắn cho trẻ em
Khoá học lập trình game con rắn cho trẻ em 


