RabbitMQ vs Kafka – Hai Cách Truyền Tải Khác Nhau

RabbitMQ là một hệ thống message queue phân tán. Gọi là phân tán bởi vì nó được chạy trên một cụm các nút trong đó hàng đợi được trải dài trên các nút và được sao lưu để có khả năng chịu lỗi và tính khả dụng cao. Nó triển khai AMQP 0.9.1 và cung cấp các giao thức khác như AMQP 1.0, STOMP, MQTT và HTTP thông qua plugin.
RabbitMQ sử dụng cả cách truyền tải truyền thống lẫn mới lạ. Truyền thống là nó hướng đến các message queue xung quanh, còn mới lạ là ở khả năng định tuyến linh hoạt của nó. Khả năng định tuyến là thế mạnh bất diệt của RabbitMQ. Bản thân nó vốn đã có các ưu điểm như nhanh, đáng tin cậy và dễ mở rộng, nhưng chính tính năng định tuyến mới làm nó nổi bật so với các công nghệ truyền tin khác.
Exchanges và Queues
Tổng quan đơn giản như sau:
- Các publisher gửi thông điệp đến các exchange.
- Exchange định tuyến thông điệp đến Queue (hàng đợi) và các exchange khác.
- RabbitMQ gửi ack đến publisher khi đã nhận được thông điệp.
- Consumer duy trì kết nối TCP liên tục với RabbitMQ và khai báo những queue mà họ sẽ dùng.
- RabbitMQ đẩy các thông điệp đến consumer.
- Consumer gửi ack xác nhận thành công hoặc thất bai.
- Thông điệp được xóa khỏi queue sau khi gửi thành công.
Nhưng đừng vội nghĩ rằng Exchange là một thứ gì đó. Một sai lầm phổ biến trong RabbitMQ là người ta nghĩ rằng Exchange là một thứ mà họ có thể gửi đến. Thực tế thì các Exchange là những quy tắc định tuyến. Khi bạn gửi một thông điệp đến một kênh, nó sẽ dùng các quy tắc định tuyến (Exchange) để quyết định nơi thông điệp sẽ được gửi đến. (Việc sử dụng từ Exchange là không hay lắm, lẽ ra nó nên là “rule” hoặc “routing rule”).
Bây giờ ta sẽ xem qua mô hình kiến trúc khi ta có một Publisher, một Exchange, một Queue và một Consumer

Hình 1. Một Publisher với Một Consumer
Vậy sẽ thế nào khi bạn có nhiều Publisher cho cùng một thông điệp? Hoặc có nhiều Consumer và cả thảy chúng đều muốn nhận về tất cả thông điệp?
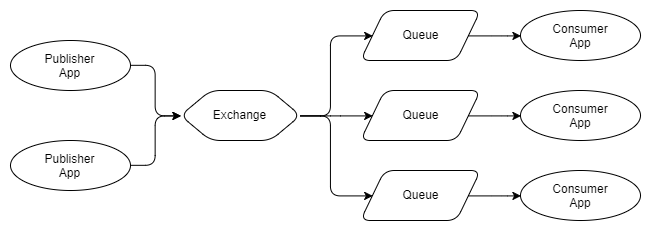
Hình 2 – Nhiều Publisher và Nhiều Consumer độc lập
Như bạn có thể thấy, khi Publisher gửi thông điệp đến cùng một Exchange, nó sẽ định tuyến thông điệp đến ba Queue, mỗi cái đều có một Consumer. Trong RabbitMQ, Queue cũng có thể cho phép các Consumer khác nhau nhận từng thông điệp. Như hình dưới đây:
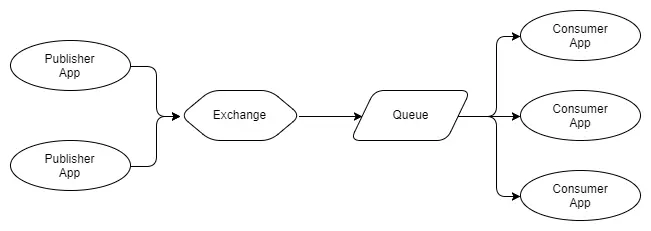
Hình 3 – Nhiều Publisher và Nhiều Consumer cạnh tranh
Ở hình trên ta có 3 consumer tất cả cùng nhận từ một queue. Chúng được gọi là những Consumer cạnh tranh, tức là chúng sẽ cạnh tranh để nhận thông điệp từ 1 hàng đợi. Chúng ta mong đợi rằng trung bình mỗi consumer sẽ nhận được 1 phần 3 số thông điệp của queue. Ta có thể sử dụng những consumer cạnh tranh để mở rộng quy trình xử lý thông điệp của mình với RabbitMQ, đơn giản như sau, chỉ cần thêm hoặc xóa consumer theo yêu cầu. Cho dù bạn có bao nhiều consumer cạnh tranh thì RabbitMQ cũng sẽ đảm bảo rằng các thông điệp sẽ được chuyển đến 1 consumer duy nhất.
Ta có thể kết hợp hình 2 và hình 3 để có được nhiều nhóm Consumer cạnh tranh trong đó mỗi nhóm nhận mọi thông điệp.
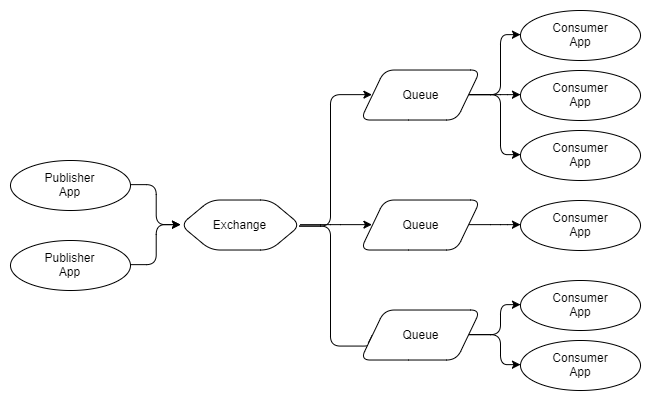
Hình 4. Nhiều Publisher, Nhiều Queue với các Consumer cạnh tranh.
Mũi tên ở giữa exchange và queue được gọi là binding và ta sẽ nói về nó sâu hơn ở phần 2.
Sự bảo đảm
RabbitMQ có thể đảm bảo về việc “truyền tải ít nhất 1 lần” hoặc “truyền tải nhiều nhất 1 lần” nhưng nó sẽ không đảm bảo “truyền tải chính xác 1 lần”. Ta sẽ hiểu sâu về điều này ở bài 4 của series.
Các thông điệp được gửi theo thứ tự trong hàng đợi. Nhưng điều này không bảo việc hoàn thành quá trình xử lý thông điệp sẽ khớp chính xác với thứ tự gửi khi bạn có Consumer cạnh tranh. Đây không phải là lỗi của RabbitMQ mà là thực tế cơ bản của việc xử lý song song một tập hợp các thông điệp được sắp xếp theo thứ tự. Vấn đề này có thể giải quyết bằng Consistent Hashing (Băm nhất quán) mà bạn sẽ thấy ở phần tiếp theo Pattern và Topology.
Push và Prefetch
RabbitMQ đẩy (push) các thông điệp đến consumer trong một stream. Ở đây vẫn có một Pull API nhưng hiệu suất của nó rất tệ, vì mỗi thông điệp sẽ yêu cầu một chuyến đi khứ hồi request-response.
Hệ thống thiên về push có thể khiến Consumer bị ngợp nếu lượng thông điệp đến hàng đợi nhanh hơn mức consumer có thể xử lý chúng. Vì vậy, để tránh điều này, mỗi consumer có thể cấu hình giới hạn tìm nạp trước (prefetch), còn gọi là giới hạn QoS. Về cơ bản thì đây là số lượng thông điệp chưa xác nhận mà consumer có thể có bất cứ lúc nào. Nó hoạt động như một công tắc an toàn, khi mà consumer bị tụt lại phía sau.
Vậy tại sao lại là push mà không phải pull ? Thứ nhất, nó rất tuyệt vời với độ trễ thấp. Thứ hai, nếu chúng ta có những consumer cạnh tranh, ý tưởng sẽ là phân phối tải đồng đều giữa chúng. Nếu để Consumer tự kéo thông điệp về thì mỗi consumer có thể kéo số lượng thông điệp không giống nhau, dẫn đến việc phân phối không đồng đều gây ra độ trễ cao và mất thứ tự thông điệp khi xử lý. Vì thế, Pull API của RabbitMQ chỉ cho phép kéo về một thông điệp tại một thời điểm, nhưng điều này lại ảnh hưởng nghiêm trong đến hiệu suất. Những yếu tố này khiến RabbitMQ nghiên về cơ chế push hơn. Đây cũng là một trong những giới hạn mở rộng của RabbitMQ.
Định tuyến
Như đã đề cập ở trên, Exchange về cơ bản là các quy tắc định tuyến cho thông điệp. Các thông điệp theo trật tự đi từ một Publisher đến một Queue hoặc Exchange khác, sẽ cần một liên kết (binding). Các exchange khác nhau cần các liên kết khác nhau. Có nhiều kiểu Exchange và kiểu liên kết của nó.
- Fanout: định tuyến đến tất cả queue và exchange có liên kết với exchange đó. Đây là mô hình tiêu chuẩn Pub-Sub.
- Direct: định tuyến thông điệp dựa trên một khóa định tuyến (routing key) mà thông điệp mang theo, được thiết lập bởi Publisher. Một khóa định tuyến là một chuỗi ngắn. Thông điệp được truyền trực tiếp đến các queue hoặc exchange có khóa liên kết (binding key) ứng với khóa định tuyến.
- Topic: định tuyến thông điệp dựa trên một khóa định tuyến, nhưng chỉ cần khớp ở ký tự đại diện.
- Header: RabbitMQ cho phép một header tùy chỉnh có thể thêm vào thông điệp. Exchange sẽ định tuyến thông điệp theo các giá trị trong header. Mỗi liên kết bao gồm các giá trị tương ứng chính xác với header. Nhiều giá trị có thể được thêm vào một liên kết với TẤT CẢ giá trị hoặc BẤT KỲ giá trị nào được yêu cầu để tương ứng.
- Consitent Hashing: Đây là một Exchange băm các khóa định tuyến hoặc header của thông điệp, sau đó đưa ra định tuyến đến một queue. Kiểu Exchange này rất hữu ích khi bạn cần xử lý các thông điệp đồng thời đảm bảo trật tự cho chúng với các consumer cạnh tranh.
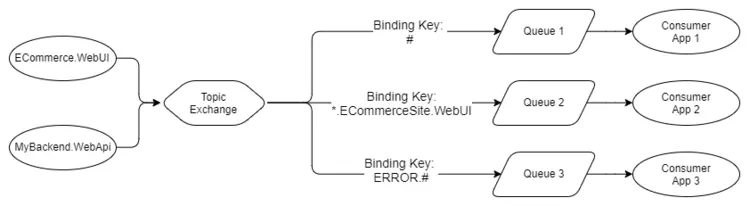
Ta sẽ tìm hiểu kỹ hơn về định tuyến ở bài 2, nhưng trên đây là một ví dụ về Topic Exchange. Piblisher đẩy các log lỗi với một khóa định tuyến dạng LEVEL.AppName.
- Queue 1 sẽ nhận tất cả thông điệp vì nó sử dụng ký tự đại diện là
#. - Queue 2 sẽ nhận bất kỳ log nào của ứng dụng Ecommerce.WebUI. Nó sử dụng ký tự
*để bao hàm mọi cấp độ log. - Queue 3 sẽ nhận tất cả log lỗi từ bất kỳ ứng dụng nào. Nó sử dụng ký tự
#để bao hàm tất cả các ứng dụng.
Với bốn kiểu định tuyến và cho phép các Exchange định tuyến đến các Exchange khác, RabbitMQ cung cấp một pattern cho trao đổi thông điệp mạnh mẽ và linh hoạt. Tiếp theo ta sẽ đề cập đến trao đổi tin chết, exchange và queue tạm thời.
Trao đổi tin chết – Dead Letter Exchange
Ta có thể cấu hình để gửi thông điệp đến một exchange với các điều kiện như sau:
- Queue vượt qua số lượng thông điệp mà cấu hình cho phép.
- Queue vượt quá số byte mà cấu hình cho phép.
- TTL (Time-To-Live) của thông điệp đã hết hạn. Publisher có thể đặt lại thời gian tồn tại của thông điệp và queue cũng có thể có một TTL. Cái nào ngắn hơn sẽ được áp dụng.
Chúng ta có thể tạo ra một queue có liên kết với dead letter exchange, và các thông điệp sẽ được lưu trữ ở đó cho đến khi có hành động được thực hiện. Bạn có thể tìm hiểu kỹ hơn về cấu trúc triển khai ở bài viết này, ở đó tất cả các thư chết sẽ được chuyển đến trung tâm dọn dẹp, nơi nhóm hỗ trợ có thể quyết định hành động nên thực hiện.
Giống như nhiều chức năng khác của RabbitMQ, trao đổi tin chết cung cấp các pattern mở rộng. Ta có thể sử dụng TTL và trao đổi tin chết để triển khái các deplay queue và retry queue bao gồm cả dự phòng theo cấp số nhân.
Exchange và Queue tạm thời
Exchange và queue có thể được tạo động và cung cấp các đặc điểm cho tự động xóa. Sau một khoảng thời gian nhất định chúng có thể tự hủy. Điều này cho phép các Pattern như hàng đợi trả lời tạm thời (ephermal reply queue) cho RPC dựa trên thông điệp.
Plugins
Plugin đầu tiên mà bạn sẽ muốn tải về là Management Plugin, nó cung cấp một HTTP Server, với giao diện Web và REST API. Nó thực sự đơn giản để cài đặt và cho chúng ta một giao diện UI có thể dễ dàng thiết lập và khởi chạy. Việc triển khai script thông qua REST API cũng dễ dàng tương tự.
Một vài plguin khác:
- Consistent Hashing Exchange, Sharding Plugin.
- STOMP, MQTT.
- Webhooks.
- Extra Exchange Types.
- SMTP.
- Top.
Còn nhiều điều nữa về RabbitMQ, nhưng ta đã có những tài liệu cơ bản đủ tốt để cung cấp cho ta những gì ta cần và có thể làm với RabbitMQ. Bây giờ, ta sẽ xem xét qua Kafka, ứng dụng này có cách tiếp cận hoàn toán khác đối với việc trao đổi thông điệp cũng như các tính năng tuyệt vời khác.
Apache Kafka là gì?

Kafka là một hệ thống commit log nhân rộng và phân tán. Kafka không có khái niệm về Queue từ đầu, mà nó được xem như một hệ thống truyền tin. Trong một thời gian dài, Queue được dùng đồng nghĩa với một hệ thống truyền tin. Bây giờ ta sẽ bóc tách kỹ về các từ commit log, phân tán và nhân rộng.
- Phân tán: bởi vì Kafka được triển khai như một cụm các nút, dành cho cả việc mở rộng và khả năng chịu lỗi.
- Nhân rộng (sao lưu) vì các thông điệp sẽ được sao lưu lại trên nhiều nút (server).
- Commit log vì các thông điệp được lưu tại các phân vùng, chỉ nối thêm các log được gọi là các Topic. Khái niệm log có thể xem tính năng nổi bật nhất của Kafka.
Hiểu về log (Topic) và phân vùng (Partition) của nó là chìa khóa để có thể hiểu được Kafka. Thế một phân vùng log thì khác như thế nào với một tập hợp queue? Hãy xem hình bên dưới.
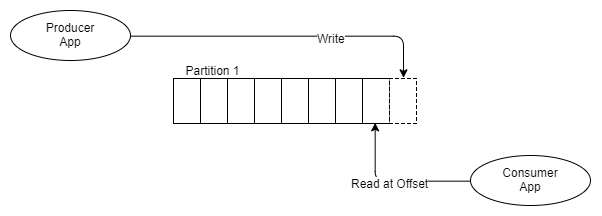
Hình 6. Một product, một partition và một consumer
Thay vì đặt thông điệp vào hàng đợi FIFO và theo dõi trạng thái của thông điệp đó như Queue trong RabbitMQ, thì Kafka chỉ thêm nó vào log và thế là xong. Thông điệp vẫn ở đó dù nó được xử lý một lần hay hàng nghìn lần. Nó chỉ bị xóa theo chính sách lưu dữ liệu (thường là theo window time period). Vậy thế nào là một consumer?
Mỗi consumer theo dõi vị trí của nó trong log, nó có một con trỏ tới thông điệp cuối cùng được xử lý, và con trỏ này được gọi là offset. Consumer duy trì offset này thông qua các thư viện client và phụ thuộc vào phiên bản Kafka, mà offset được lưu trữ trong ZooKeeper hoặc chính Kafka. ZooKeeper là một công nghệ phân tán sử dụng được dùng cho nhiều hệ thống hỗ trợ Leader Election. Kafka dựa vào ZooKeeper để quản lý trạng thái của cụm.
Điều tuyệt vời về mô hình log này là nó ngay lập tức loại bỏ sự phức tạp xung quanh trạng thái gửi tin nhắn và quan trọng hơn là với Consumer, nó cho phép họ thực hiện lại và sử dụng thông điệp từ offset trước đó. Ví dụ, bạn triển khai một dịch vụ để tính toán hóa đơn đặt phòng được đặt bởi khách hàng, invoice service. Dịch vụ có lỗi và đã tính toán sai các hóa đơn trong 24 giờ qua.Với RabbitMQ, bạn sẽ cần làm là bằng cách nào đó gửi lại các yêu cầu đặt phòng và chỉ cho dịch vụ (invoice service) biết điều đó. Nhưng với Kafka, bạn chỉ cần đơn giản là di chuyển offset cho consumer quay lại 24 giờ.
Bây giờ, ta sẽ xem nó trông như thế nào khi ta có 1 Topic với 1 Partition và 2 consumer, mà mỗi cái cần nhận tất cả thông điệp.
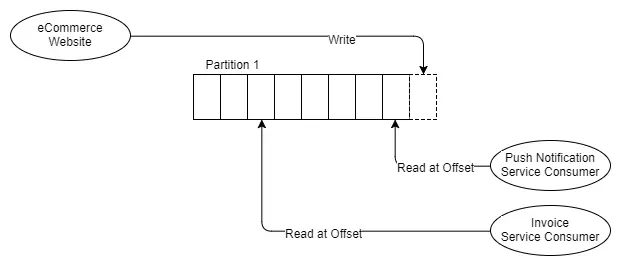
Hình 7. Một Producer, 1 Partition và 2 Consumer độc lập.
Như bạn có thể thấy từ mô hình, 2 consumer độc lập nhận từ cùng một partition, nhưng chúng đọc từ 2 offset khác nhau. Điều này có thể do dịch vụ đặt đơn hàng mất nhiều thời gian để xử lý thông điệp hơn dịch vụ thông báo, hoặc do dịch vụ đơn hàng bị sập trong một khoảng thời gian, hoặc nó đã có lỗi và cần quay về offset vài giờ trước đó.
Bây giờ nếu ta cần mở rộng dịch vụ đơn hàng thành 3 nhưng vẫn duy trì tốc độ truyền tin. Với RabbitMQ ta sẽ triển khai thành 2 ứng dụng và xử lý từ một queue. Nhưng Kafka không hỗ trợ các consumer cạnh tranh trên cùng 1 partition, đơn vị song song của Kafka chính là partion. Thế nên với 3 consumer là dịch vụ đơn hàng ta sẽ cần ít nhất 3 partition.
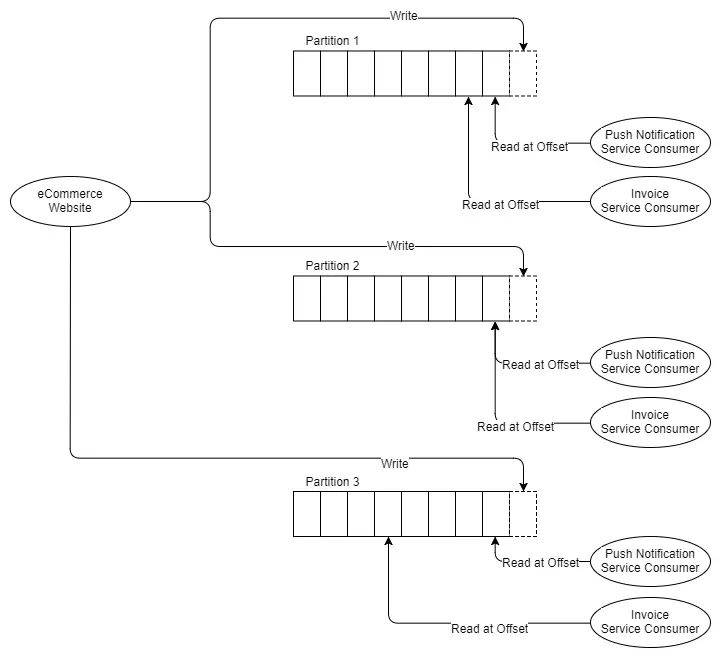
Hình 8: Ba partition với hai tập hợp của 3 consumers.
Như vậy ta sẽ cần nhiều partition hơn mỗi khi consumer được mở rộng. Nói thêm về partition.
Partition và Consumer Group
Mỗi partition là một cấu trúc dữ liệu riêng biệt dùng để đảm bảo thứ tự của thông điệp. Điều quan trọng cần nhớ là: thứ tự thông điệp chỉ được đảm bảo trong một partion. Điều này có thể gây ra những vấn đề về sau, giữa nhu cầu thứ tự thông điệp và hiệu suất vì đơn vị song song cũng là partition. Một partition không thể hỗ trợ các consumer cạnh tranh, nên với ứng dụng đơn hàng của chúng ta chỉ có thể có 1 dịch vụ với 1 partition.
Thông điệp có thể được định tuyết đến partition theo vòng tròn hoặc thông qua hàm băm:
hash (khóa thông điệp) % số lượng partition
Sử dụng hàm băm có một số lợi ích là ta có thể thiết kế khóa thông điệp sao cho các thông điệp cùng thuộc một thực thể, như đặt phòng chẳng hạn, luôn đi đến cùng một partition. Điều này cho phép ta áp dụng được nhiều pattern khi thiết kế, cũng như đảm bảo được thứ tự của thông điệp.
Consumer Group tương tự các consumer cạnh tranh của RabbitMQ. Mỗi consumer trong group là một thực thể của cùng một ứng dụng và sẽ xử lý một tập con của các thông điệp trong Topic. Trong khi những consumer cạnh tranh của RabbitMQ sử dụng cùng 1 queue. thì mỗi consumer trong group xử lý từ một partition khác nhau ở cùng 1 topic. Ví dụ như trên, 3 thực thể của dịch vụ đơn hàng là cùng thuộc về một Consumer Group.
Ở điểm này RabbitMQ trông linh động hơn với việc đảm bảo thứ tự thông điệp trong một queue và khả năng liền mạnh để đối phó với số lượng consumer thay đổi.
Tuy vậy Kafka có một lợi thế mà về sau RabbitMQ phải thêm vào liên quan đến thứ tự thông điệp và tính song song. RabbitMQ duy trì thứ tự toàn cục của toàn bộ hàng đợi mà không có cách nào để duy trì thứ tự đó trong quá trính xử lý song song của hàng đợi đó. Kafka không cung cấp thứ tự toàn cục nhưng vẫn cung cấp thứ tự ở cấp partition. Vì vậy, nếu bạn chỉ cần thứ tự các thông điệp liên quan thì Kafka cung cấp cả thứ tự thông điệp được truyền và thứ tự thông điệp được xử lý.
Tưởng tượng bạn có các thông điệp cho biết trạng thái cuối cùng của một yêu cầu đặt hàng, bạn muốn luôn luôn xử lý tuần tự các thông điệp của của yêu cầu đó (theo thứ tự thời gian). Nếu partition theo bookingId, thì tất cả thông điệp của yêu cầu đặt phòng đấy sẽ đến cùng 1 partition, và ta sẽ có các thông điệp theo đúng thứ tự. Thế nên, bạn có thể tạo một số lượng lớn các partition, làm cho quá trình xử lý của chúng ta vẫn song song và vẫn đảm bảo được thứ tự cho các thông điệp.
RabbitMQ cũng làm được điều này với Consistent Hashing Exchange, nó sẽ phân phối thông điệp trên các queue theo cách tương tự. Mặc dù Kafka thực thi quy trình xử lý theo thứ tự này bởi thực tể là 1 consumer trong group chỉ có thể dùng 1 partition. Về phần RabbitMQ thì nó cung cấp Single Active Consumer (SAC) để ngăn chặn nhiều consumer chủ động sử dụng queue cùng lúc (ngay cả khi consumer đã đăng ký với queue), nhưng nó không cung cấp sự phối hợp của consumer trên nhiều queue.
Quay lại Kafka, ở đây cũng có một vấn đề là khi bạn thay đổi số lượng partition, các thông điệp cho bookingId là 1000 bây giờ sẽ chuyển đến một partition khác, vì vậy các thông điệp có orderId là 1000 bây giờ sẽ tồn tại trong 2 partition. Tùy thuộc vào cách bạn xử lý thông điệp của mình, điều này khá nhức đầu. Chúng ta sẽ đề cập đến chủ đề này chi tiết hơn ở phần 4 của series.
Push và Pull
RabbitMQ sử dụng mô hình push và ngăn chặn các consumer thông qua giới hạn prefetch được cấu hình cho consumer. Điều này rất hữu ích với việc truyền tải thông điệp có độ trễ thấp và hoạt động tốt cho kiến trúc hàng đợi của RabbitMQ. Mặt khác, Kafka sử dụng mô hình pull trong đó Consumer yêu cầu hàng loạt thông điệp từ một offset nhất định. Để trách các vòng lặp khi không có thông điệp nào tồn tại ngoài offset hiện tại, Kafka cho phép long-polling.
Mô hình pull phù hợp với Kafka do các partition của nó. Vì Kafka đảm bảo thứ tự thông điệp trong một partition sẽ không có consumer cạnh tranh, ta có thể tận dụng việc gộp thông điệp để truyền tin hiệu quả hơn mang lại thông lượng cao hơn. Điều này không có nhiều ý nghĩa đối với RabbitMQ vì chúng ta đang muốn phân phối từng thông điệp một cách nhanh nhất để đảm bảo rằng công việc được thực hiện song song đồng đều và các thông điệp được xử lý gần với thứ tự mà chúng đến trong queue.
Publish Subscribe
Kafka hỗ trợ pub-sub cơ bản với pattern mở rộng liên quan đến thực tế nó có một log và nhiều partition. Producer thêm thông điệp vào cuối của partition và consumer có thể di chuyển với offset của nó đến bất cứ nơi nào trên partition.
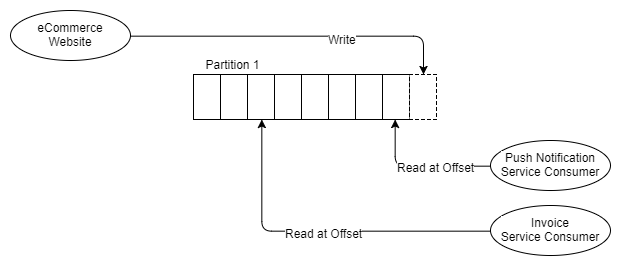
Hình 9: Các consumer với các offset khác nhau.
Kiểu mô hình này không dễ diễn giải vì có nhiều partition và consumer group, vì vậy với phần còn lại của sơ đồ Kafka, ta sẽ có kiểu sơ đồ sau:
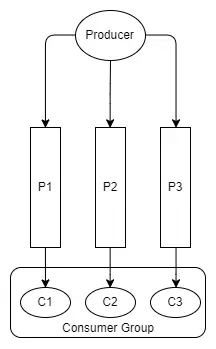
Hình 10. Một producer, 3 partion và 1 consumer group với 3 consumer.
Ta không cần phải có số lượng consumer bằng với số partion.
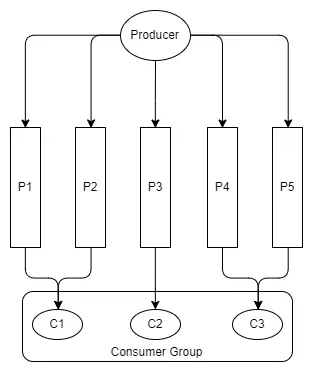
Hình 11. Các consumer đọc nhiều hơn 1 partition.
Consumer trong 1 group sẽ phối hợp để xử lý thông điệp từ partition, đảm bảo rằng 1 partition sẽ không được xử lý bởi nhiều hơn 1 consumer của 1 group.
Tương tự, nếu ta có lượng consumer nhiều hơn partition, consumer mở rộng sẽ ở trạng thái nhàn rỗi.
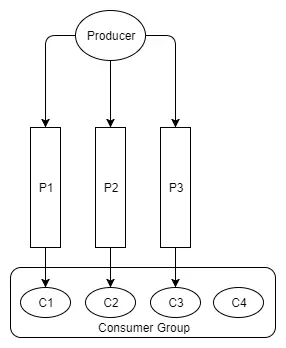
Hình 12. Một consumer nhàn rỗi.
Sau khi thêm và xóa consumer, consumer group có thể trở nên mất cân bằng. Việc tái cân bằng phân phối lại consumer càng đồng đều càng tốt trên các partition.
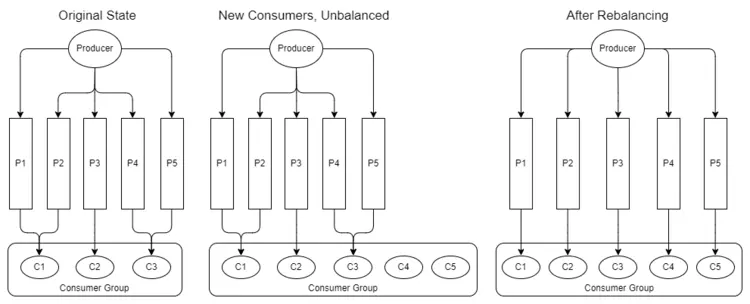
Hình 13. Thêm hoặc xóa consumer yêu cầu tái cân bằng lại.
Tái cân bằng sẽ tự động thực hiện sau khi:
- Một consumer tham gia vào group.
- Một consumer rời khởi group (có thể là tắt nguồn hoặc sập).
- Một partition được thêm vào.
Tái cân bằng sẽ mất một khoảng thời gian mở rộng độ trễ trong khi consumer không ngừng đọc hàng loạt thông điệp và được chỉ định cho các partition khác nhau. Bất kỳ trạng thái bộ nhớ nào được duy trì bởi consumer hiện tại sẽ không còn không hợp lệ. Một trong những pattern xử lý của Kafka là có thể chuyển hướng tất cả thông điệp đến một thực thể nhất định, chẳng hạn một booking trước đó, đến cùng một partition, và do có cùng một consumer. Đây được gọi là dữ liệu cục bộ. Khi tái cân bằng lại bất kỳ dữ liệu nào trong bộ nhớ, dữ liệu đó sẽ vô dụng trừ khi consumer được gán lại cho cùng một partition. Vì thế, consumer duy trì trạng thái sẽ cần duy trì trạng thái bên ngoài.
Log Compaction
Các chính sách lưu giữ dữ liệu tiêu chuẩn là các chính sách dựa trên thời gian và không gian. Ví dụ, lưu trữ tối đa thông điệp trong một tuần hoặc tối đa 50 GB. Nhưng vẫn tồn tại một chính sách lưu giữ dữ liệu khác là – log compaction. Khi log được nén lại, kết quả là chỉ có thông điệp gần đây nhất trên mỗi khóa thông điệp được giữ lại, phần còn lại sẽ bị xóa.
Hãy tưởng tượng chúng ta nhận được một thông báo chứa trạng thái đặt trước hiện tại của người dùng. Mỗi khi có thay đổi đối với việc đặt đơn hàng, một sự kiện mới sẽ được tạo với trạng thái hiện tại của đơn hàng. Topic có thể có một vài thông báo cho việc đặt đơn đó để biểu diễn rằng trạng thái của việc đặt kể từ khi nó được khởi tạo. Sau khi topic được nén, chỉ có thông điệp gần nhất liên quan đến việc đặt đơn được lưu giữ.
Tùy thuộc vào số lần đặt đơn và quy mô mỗi lần đặt, mà bạn có thể lưu trữ tất cả các lần đặt mãi mãi trong topic (trên lý thuyết). Bằng cách nén topic theo định kỳ, ta có thể đảm bảo rằng chỉ lưu trữ 1 thông điệp cho mỗi lần đặt.
Việc nén log cho phép một số pattern khác nhau mà ta sẽ khám phá ở bài 3 trong series.
Thứ tự thông điệp
Ta đã đề cập rằng có thể mở rộng quy mô và duy trì thứ tự của thông điệp với cả RabbitMQ và Kafka, nhưng với Kafka việc này dễ dàng hơn nhiều. Với RabbitMQ ta phải sử dùng Consistent Hashing Exchange và tự triển khai logic nhóm consumer theo cách thủ công bằng cách sử dụng SAC và logic hand-rolled tùy chỉnh.
Nhưng RabbitMQ có một khả năng thú vị mà Kafka không có: RabbitMQ cho phép subscriber tùy ý sắp xếp các nhóm sự kiện.
Đi sâu hơn một chút thì các ứng dụng khác nhau không thể chia sẽ queue vì khi đó chúng sẽ cạnh tranh để nhận các thông điệp. Chúng cần queue của riêng chúng. Điều này cho phép các ứng dụng tự do cấu hình queue của chúng theo bất kỳ cách nào mà chúng thấy là phù hợp. Chúng có thể định tuyến nhiều loại sự kiện từ nhiều exchange khác nhau đến queue của chúng. Điều này cho phép các ứng dụng duy trì thứ tự của các sự kiện liên quan. Những sự kiện nào muốn kết hợp có thể được cấu hình khác nhau cho từng ứng dụng.
Điều này căn bản là không thể thực hiện với hệ thống dựa trên log như Kafka bởi vì log là dạng tài nguyên chia sẽ. Nhiều ứng dụng sẽ đọc được từ một log. Vì vậy bất kỳ sự kiện liên quan nào vào một topic đều được đưa ra ở cấp độ kiến trúc hệ thống rộng lớn hơn.
Vì vậy, ở đây không có người nào là chiến thắng tuyệt đối. RabbitMQ cho phép bạn duy trì một thứ tự tương đối trên các nhóm sự kiện tùy ý và Kafka cung cấp một cách đơn giản để duy trì thứ tự trên quy mô lớn.
Kết luận
RabbitMQ cứ như một con dao Thụy Sĩ khi cung cấp một loạt các tính năng đa dạng. Với khả năng định tuyến mạnh mẽ, nó có thể loại bỏ như cầu truy xuất, deserialize và kiểm tra mọi thông điệp khi mà consumer chỉ cần một tập con. Nó cũng dễ dàng cho khả năng mở rộng hay thu gọn quy mô, bằng cách thêm và xóa consumer. Kiến trúc plugin của nó cho phép hỗ trợ các giao thức khác nhau và thêm các tính năng mới như Consitent Hashing Exchange, đây là một bổ sung quan trọng.
Nền tảng phân phối log Kafka với offset của consumer giúp ta có thể du hành thời gian. Đó là khả năng định tuyến các thông điệp của cùng một khóa đến cùng một consumer, giúp cho ta có thể xử lý thông điệp theo thứ tự và song song. Việc nén log và lưu giữ dữ liệu của Kafka cho phép ứng dụng pattern mới mà RabbitMQ đơn giản là không thể cung cấp.
Cuối cùng là đúng, Kafka có thể mở rộng quy mô hơn RabbitMQ, nhưng hầu hết chúng ta có thể dùng cả hai để xử lý khối lượng thông điệp mà không gặp ảnh hưởng gì.
(https://viblo.asia/p/rabbitmq-vs-kafka-hai-cach-truyen-tai-khac-nhau-pgjLNdYE432)
Bài viết khác

Web Security
Khái niệm Web Security Web Security là tập hợp các nguyên tắc, biện pháp và công nghệ nhằm bảo vệ website, ứng dụng web và dữ liệu khỏi các hành vi truy cập trái phép, tấn công độc hại hoặc khai thác lỗ hổng. Nó không chỉ bao gồm việc ngăn chặn hacker, mà còn […]

Markdown
Markdown là một ngôn ngữ đánh dấu nhẹ (lightweight markup language) dùng để định dạng văn bản thuần túy (plain text), thường được sử dụng trong các tài liệu như README, bài viết blog, tài liệu hướng dẫn, và cả trong GitHub, Stack Overflow, hoặc các trình soạn thảo như VS Code, Obsidian… Markdown được […]

CSS
CSS (Cascading Style Sheets – tạm dịch: Tập tin định kiểu tầng) là ngôn ngữ dùng để mô tả cách trình bày (giao diện) của một tài liệu HTML. Nói đơn giản, CSS giúp làm đẹp trang web: chỉnh màu sắc, font chữ, bố cục, khoảng cách, hiệu ứng chuyển động, v.v. CSS được phát […]

HTML
HTML (HyperText Markup Language) là ngôn ngữ đánh dấu siêu văn bản, được dùng để xây dựng cấu trúc của một trang web. Nói cách khác, HTML cho trình duyệt biết nội dung nào sẽ hiển thị và hiển thị như thế nào (như tiêu đề, đoạn văn, hình ảnh, liên kết…). Một tài liệu […]

Browser
Browser (Web Browser, Trình duyệt web) là phần mềm trên máy tính, điện thoại hoặc thiết bị thông minh, cho phép người dùng truy cập, hiển thị và tương tác với các trang web, tài nguyên Internet. Về bản chất, trình duyệt gửi các yêu cầu (HTTP/HTTPS request) đến máy chủ web, nhận về mã […]
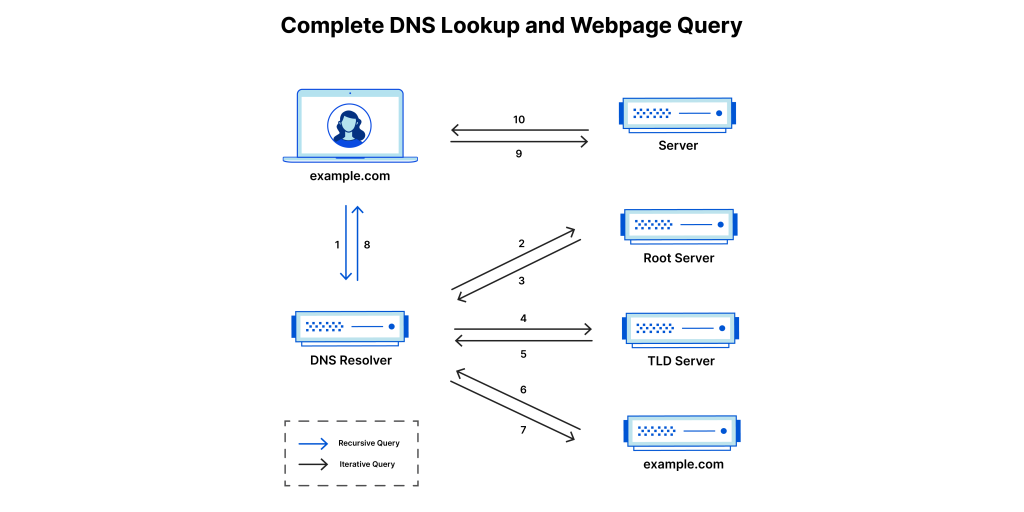
Tìm hiểu DNS
DNS là gì? DNS (Domain Name System) là một dịch vụ phân giải tên miền, giúp chuyển đổi các tên miền (ví dụ: www.ducphat.com) thành địa chỉ IP (ví dụ: 93.184.216.34) và ngược lại. Thay vì phải nhớ dãy số IP, chúng ta chỉ cần nhập tên miền, DNS sẽ tìm kiếm địa chỉ IP […]
 Khoá học lập trình game con rắn cho trẻ em
Khoá học lập trình game con rắn cho trẻ em 


