Kafka là gì?
Apache Kafka là một nền tảng phân phối sự kiện phân tán mã nguồn mở được phát triển bởi Apache Software Foundation và được viết bằng Java và Scala.
Kafka ban đầu được phát triển bởi LinkedIn và sau đó được mở nguồn cho Quỹ phần mềm Apache (Apache Software Foundation) vào đầu năm 2011. (đồng sáng lập và CEO của Confluent), Neha Narkhede (đồng sáng lập và cựu CTO của Confluent) và Jun Rao (đồng sáng lập Confluent) là các đồng sáng lập nền tảng phần mềm Kafka. Jay Kreps chọn cái tên “Kafka” (Franz Kafka – một nhà văn Đức vĩ đại thế kỷ 20) vì theo anh cái tên này có những đặc điểm phù hợp để đại diện cho công nghệ của họ.
Kafka được tạo ra để giải quyết những thách thức trong việc xử lý lượng dữ liệu khổng lồ trong thời gian thực (real-time), cho phép các ứng dụng xuất bản (publish), đăng ký (subscribe), lưu trữ (store) và xử lý (process) các luồng bản ghi (streaming event) một cách hiệu quả.
Các thành phần chính trong Kafka
Kafka event
Một Kafka event (sự kiện) ghi lại thực tế rằng “điều gì đó đã xảy ra” trên thế giới hoặc trong doanh nghiệp của bạn. Nó còn được gọi là record (bản ghi) hoặc message (thông điệp). Trong nhiều tài liệu về Kafka, việc sử dụng 3 thuật ngữ event, record và message mang nghĩa tương đương nhau.
Việc đọc và ghi dữ liệu trong Kafka thực hiện thông qua event. Mỗi event chứa một key (khoá), value (giá trị) và metadata (nếu có).
Kafka topic
Các event được tổ chức và lưu trữ lâu dài trong các topics (chủ đề). Có thể coi một topic ví như một thư mục (folder) trong hệ thống tập tin (filesystem), còn mỗi event là một tập tin (file) nằm bên trong thư mục đó.
Hình dưới cho thấy một topic có 4 partitions, với phần ghi được thêm vào cuối mỗi partition. Kafka cung cấp khả năng dự phòng (redundancy) và khả năng mở rộng (scalability) thông qua các partitions. Mỗi partition có thể được lưu trữ trên một máy chủ khác nhau, điều đó có nghĩa là một topic có thể được mở rộng theo chiều ngang trên nhiều máy chủ để cung cấp hiệu suất vượt xa khả năng của một máy chủ.

Kafka Brokers và Kafka Clusters
Kafka được chạy dưới dạng một Kafka cluster gồm một hoặc nhiều Kafka server có thể mở rộng trên nhiều data center hoặc cloud. Một Kafka server này tạo thành lớp lưu trữ, được gọi là Kafka broker.
Brokers chịu trách nhiệm quản lý bộ lưu trữ, xử lý các yêu cầu đọc và ghi cũng như sao chép dữ liệu trên toàn cluster (cụm).
Trong mỗi cluster sẽ có một broker sẽ hoạt động như một cluster controller (bộ điều khiển cụm), chịu trách nhiệm chỉ định phân vùng cho brokers và theo dõi lỗi của brokers.
Kafka Partitions và Kafka Replication
Các topic được chia thành các partitions (phân vùng), là đơn vị cơ bản của tính song song và phân phối trong Kafka. Mỗi phân vùng được lưu trữ trên một broker duy nhất và nhiều phân vùng cho phép mở rộng quy mô theo chiều ngang và cải thiện hiệu suất.
Mỗi event trong một partition được gán một offset duy nhất, bắt đầu từ 0 cho event đầu tiên trong partition và tăng dần một cho mỗi event tiếp theo. Offset được sử dụng để xác định vị trí của event trong một partition.
Kafka đảm bảo độ bền của dữ liệu bằng cách sao chép dữ liệu (replication) trên nhiều brokers. Mỗi partition có thể có một hoặc nhiều replica (bản sao) trên các brokers khác nhau, ngăn ngừa mất dữ liệu trong trường hợp broker lỗi.

Mỗi partition có một broker được chỉ định làm leader, nắm quyền sở hữu partition đó, trong khi các brokers còn lại lưu trữ các replicas (bản sao) của phân vùng đó được gọi là followers.
Nếu leader broker xảy ra lỗi, một trong những followers có dữ liệu cập nhật sẽ được chọn làm leader mới. Quá trình này được gọi là leader failover (chuyển đổi dự phòng lãnh đạo), nhằm đảm bảo tính khả dụng của dữ liệu.
Kafka Producers
Kafka Producer là một client appication (ứng dụng khách), publish (xuất bản) event vào một topic cụ thể trong Kafka và luôn ghi vào leader broker. Theo mặc định, producers không quan tâm tới event được ghi ở partition nào mà sẽ publish đều event trên tất cả partition của một topic. Trong vài trường hợp, một producer sẽ gửi trực tiếp event tới các partition cụ thể.
Producers kết nối tới Kafka Brokers thông qua giao thức mạng TCP. Đây là kết nối hai chiều (bi-directional connection).
Kafka Consumers
Kafka consumer là một client application (ứng dụng khách), subscribe (đăng ký) một hoặc nhiều Kafka topics và đọc các bản ghi theo thứ tự chúng được tạo ra. Consumers đọc dữ liệu theo thời gian thực hoặc theo tốc độ của riêng chúng, cho phép các ứng dụng phản ứng với các sự kiện khi chúng xảy ra.
Consumers kết nối tới Kafka Brokers thông qua giao thức mạng TCP. Đây là kết nối hai chiều (bi-directional connection).
Consumers hoạt động trong một consumer group, làm việc cùng nhau để xử lý dữ liệu từ các partitions, cung cấp khả năng mở rộng theo chiều ngang và cho phép nhiều phiên bản của cùng một ứng dụng xử lý dữ liệu đồng thời.
Kafka APIs
Apache Kafka APIs bao gồm 5 loại APIs chính:
- Kafka Producer API cho phép các ứng dụng gửi luồng dữ liệu đến các Topics trong Kafka clusters.
- Kafka Consumer API cho phép các ứng dụng đọc luồng dữ liệu từ các Topics trong Kafka clusters.
- Kafka Streams API cho phép chuyển đổi luồng dữ liệu từ Topic đầu vào sang Topic đầu ra.
- Kafka Connect API cho phép triển khai các trình kết nối liên tục kéo từ một số hệ thống nguồn hoặc ứng dụng vào Kafka hoặc đẩy từ Kafka vào một số hệ thống hoặc ứng dụng background.
- Kafka Admin API cho phép quản lý và kiểm tra các Topics, Brokers và các đối tượng Kafka khác.
Ưu điểm của Kafka
- Hiệu suất cao: Có thể xử lý hàng triệu message mỗi giây với độ trễ thấp.
- Khả năng mở rộng tốt: Dễ dàng mở rộng bằng cách thêm broker và partition.
- Chịu lỗi (fault-tolerant): Dữ liệu được replicate trên nhiều broker để tránh mất mát khi node gặp sự cố.
- Lưu trữ bền vững: Message được lưu như log files, có thể đọc lại sau theo thời gian định sẵn (retention).
- Đảm bảo thứ tự: Dữ liệu trong cùng một partition luôn được xử lý theo đúng thứ tự gửi vào.
- Tách biệt producer và consumer: Cho phép các thành phần hệ thống hoạt động độc lập, dễ tích hợp.
- Xử lý thời gian thực: Hỗ trợ các hệ thống stream processing như Kafka Streams, Flink, Spark Streaming.
- Tích hợp tốt với hệ sinh thái: Dễ kết nối với Hadoop, Elasticsearch, Flink, Spark, hệ CSDL, v.v.
- Hỗ trợ bảo mật: Có xác thực SSL, SASL và phân quyền truy cập thông qua ACL.
- Hoạt động như hệ thống pub/sub hiện đại: Linh hoạt trong nhiều kiến trúc hệ thống khác nhau (batch, stream, microservices,…).
Ứng dụng của kafka
- Xử lý dữ liệu thời gian thực: Phân tích hành vi người dùng, logs, giao dịch ngay khi xảy ra.
- Giao tiếp giữa các microservices: Truyền sự kiện giữa các service theo mô hình event-driven.
- Hệ thống log tập trung: Thu thập log từ nhiều ứng dụng hoặc server vào một nơi xử lý tập trung.
- Hệ thống theo dõi (monitoring): Thu thập và xử lý logs, metrics từ hệ thống và thiết bị.
- ETL và Data Pipeline: Làm trung gian luân chuyển dữ liệu giữa các hệ thống (CSDL, warehouse…).
- Event sourcing: Ghi lại toàn bộ sự kiện hệ thống để khôi phục hoặc phân tích.
- Ứng dụng IoT: Nhận dữ liệu cảm biến từ hàng nghìn thiết bị và xử lý theo thời gian thực.
- Ứng dụng tài chính, ngân hàng: Theo dõi giao dịch, phát hiện gian lận, xử lý realtime.
- Ứng dụng thương mại điện tử: Quản lý đơn hàng, giỏ hàng, trạng thái vận chuyển, thông báo…
- Ứng dụng game online / mạng xã hội: Truyền dữ liệu người dùng như chat, hành động game, tương tác…
Tham khảo: Kafka là gì? Các thành phần trong Kafka | 200Lab Blog
Bài viết khác

Blockchain
Blockchain là gì? Blockchain là một công nghệ sổ cái phân tán (distributed ledger) lưu trữ dữ liệu dưới dạng các khối (blocks) được liên kết với nhau theo chuỗi (chain) bằng các hàm băm mật mã (cryptographic hash). Mỗi khối chứa danh sách các giao dịch, dấu thời gian, và tham chiếu đến khối […]

Computer Graphics
1. Ray Tracing Là một kỹ thuật mô phỏng ánh sáng trong đồ họa máy tính nhằm tạo ra hình ảnh cực kỳ chân thực. Phương pháp này dựa trên việc mô phỏng hành trình của các tia sáng từ mắt người (camera) đi vào không gian 3D, và tính toán cách chúng tương tác […]

Tìm hiểu RabbitMQ
RabbitMQ là gì? RabbitMQ là một message broker, triển khai giao thức AMQP (Advanced Message Queuing Protocol). Nhiệm vụ chính là tiếp nhận, lưu trữ tạm thời và chuyể n tiếp message giữa các Producer (gửi) và Consumer (nhận). Mục đích sử dụng RabbitMQ: phân tách các thành phần khác nhau trong hệ thống, xử […]

So sánh GORM vs go-pg vs Bun
Cộng đồng GORM Là ORM phổ biến nhất trong cộng đồng Go. Có nhiều tài liệu, ví dụ, StackOverflow câu trả lời, và nhiều package hỗ trợ mở rộng. Nhiều developer đã từng dùng Gorm. go-pg Từng rất phổ biến khi chỉ dùng PostgreSQL, nhưng đang bị Bun thay thế dần. Ít được duy trì […]
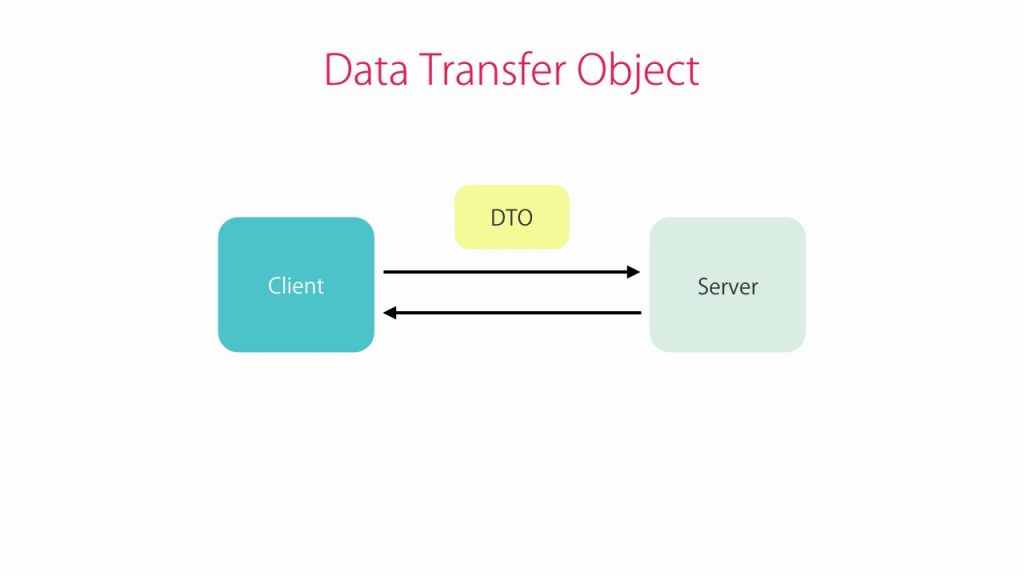
Sử dụng Request/Response trong ứng dụng RESTful mô hình MVC
DTO là gì? DTO (Data Transfer Object) là một object trung gian dùng để truyền dữ liệu giữa client – server hoặc giữa các service trong ứng dụng web/API theo kiến trúc RESTful API. DTO chỉ chứa các thông tin cần thiết mà client hoặc service khác cần (ví dụ: Login Form chỉ cần thông […]

Docker
Docker là gì? Docker là một nền tảng mã nguồn mở cho phép bạn đóng gói, phân phối và chạy ứng dụng bên trong các “container” – những môi trường ảo nhẹ, cô lập nhưng vẫn chia sẻ nhân hệ điều hành của máy chủ. Khái niệm then chốt ở đây là “containerization”: thay vì […]
 Khoá học lập trình game con rắn cho trẻ em
Khoá học lập trình game con rắn cho trẻ em 


