What is Compound indexes in PostgreSQL?
A compound index (also known as a composite index or a multi-column index) refers to an index that is created on two or more columns of a table. It allows PostgreSQL to quickly find rows that match a query condition based on the values in multiple columns, which can be useful for queries that involve multiple conditions that are frequently used together.
In PostgreSQL, a compound index is an index that contains multiple columns. It allows you to index on more than one column at a time and can be helpful in improving the performance of certain queries.
To create a compound index in PostgreSQL, you can use the CREATE INDEX statement and specify the columns you want to index in the index definition.
Here is an example of creating a compound index on two columns in a table:
CREATE INDEX idx_compound ON my_table (column1, column2);
This creates an index named “idx_compound” on the “my_table” table, which indexes both “column1” and “column2”.
When using a compound index, the order of the columns can be important. PostgreSQL uses the leftmost column in the index for sorting and filtering operations. For example, if you have a compound index on columns (A, B, C), the index can be used to satisfy queries that filter on A alone or on both A and B, but it cannot be used for queries that only filter on B or C.
Indexing algorithm for Compound indexes in PostgreSQL
In PostgreSQL, there are several indexing methods available for creating compound indexes, including:
– B-tree (the default indexing method)
– Hash
– GiST (Generalized Search Tree)
– SP-GiST (Space-Partitioned Generalized Search Tree)
– GIN (Generalized Inverted Index)
– BRIN (Block Range INdex)
Each indexing method uses a different algorithm for combining the values of multiple columns into a single index entry.
The B-tree indexing method, which is the most commonly used indexing method in PostgreSQL, works by concatenating the values of the indexed columns into a single string, and then storing this string as the index key. The index is then organized as a balanced tree structure, with each node containing a range of keys that fall between the keys of its parent node.
For example, if you have a compound index on columns (A, B, C), the B-tree indexing method would concatenate the values of A, B, and C into a single string for each row in the table, and then store these strings in the index in sorted order. When you query the index, PostgreSQL can use the index to efficiently search for rows that match a given set of values for A, B, and/or C.
Other indexing methods, such as GiST and GIN, use more complex algorithms for combining the values of multiple columns into a single index entry. These indexing methods are generally used for more specialized data types, such as geometric data or full-text search data.
Compound indexes optimize use case story
For example, here is the case when we need to get orders from a customer and between a time range
SQL query
SELECT * FROM orders WHERE customer_id = 123 AND order_date BETWEEN '2022-01-01' AND '2022-12-31'
We will analyze how that query could benefit from a compound index:
Assuming that the `orders` table has millions of rows, a single index on either `customer_id` or `order_date` may not be sufficient to provide efficient query performance. However, creating a compound index on both columns can significantly speed up this query.
To create a compound index on `customer_id` and `order_date`, you can use the following SQL command:
CREATE INDEX idx_orders_customer_date ON orders (customer_id, order_date);
When PostgreSQL processes the query, it can use the compound index to quickly identify the subset of rows that match both criteria, rather than having to scan the entire table. The compound index can be used because it can satisfy both the `customer_id = 123` and `order_date BETWEEN ‘2022-01-01’ AND ‘2022-12-31’` conditions with a single index lookup.
What if we use single index for the above case ?
For the SQL query I provided for the case above:
SELECT * FROM orders WHERE customer_id = 123 AND order_date BETWEEN '2022-01-01' AND '2022-12-31'
We can still use a single index to improve query performance.
If you have to choose one of the two columns to create an index on, it’s generally better to choose the column with higher selectivity, which is the one that has more unique values. In this case, assuming that `customer_id` has higher selectivity than `order_date`, you can create an index on `customer_id` like this:
CREATE INDEX idx_orders_customer ON orders (customer_id);
This index will allow PostgreSQL to quickly find all the rows with `customer_id = 123`, and then filter those rows further by the `order_date BETWEEN ‘2022-01-01’ AND ‘2022-12-31’` condition using a sequential scan.
Note that this approach may not be as efficient as a compound index, as it may require scanning a larger number of rows to find those that meet the `order_date` condition. However, it can still be a significant improvement over not having an index at all.
So, it’s always a good idea to evaluate the selectivity of the columns involved in the query, and create indexes on the ones that have the highest selectivity. If you have more than one column with high selectivity, you may consider creating a compound index that includes all those columns.
What if we use two single indexes for the above case ?
Using two single indexes can still improve query performance, but it may not be as efficient as a compound index in this case.
You can create two separate single-column indexes on `customer_id` and `order_date` like this:
CREATE INDEX idx_orders_customer ON orders (customer_id); CREATE INDEX idx_orders_date ON orders (order_date);
PostgreSQL can use each of these indexes to identify the subset of rows that match either `customer_id = 123` or `order_date BETWEEN ‘2022-01-01’ AND ‘2022-12-31’`. However, PostgreSQL will need to perform a separate index scan for each index, and then combine the results using an additional operation, which can be less efficient than a single compound index.
To ensure that PostgreSQL uses both indexes, you can use the `ENABLE_SEQSCAN` option to disable sequential scans:
SET enable_seqscan = off; SELECT * FROM orders WHERE customer_id = 123 AND order_date BETWEEN '2022-01-01' AND '2022-12-31'; SET enable_seqscan = on;
This will force PostgreSQL to use only the indexes to find the matching rows, and not use sequential scans. However, this approach may still be slower than using a compound index because it requires two separate index scans and additional processing to combine the results.
So, using multiple single-column indexes can be a good strategy when you have different queries that involve different combinations of columns, and you want to optimize each query separately. However, for queries that involve multiple conditions that are frequently used together, a compound index can provide more efficient query performance.
Cost of Compound index in PostgreSQL
The cost of a compound index in PostgreSQL depends on several factors, including the size of the table, the number of columns included in the index, and the selectivity of each column.
When PostgreSQL evaluates a query that involves a compound index, it uses statistics about the distribution of data in the index to estimate the cost of various query plans. The estimated cost takes into account factors such as the number of disk I/O operations required to read the index, the number of rows that need to be filtered based on the index conditions, and the estimated cost of any additional processing required to complete the query.
The cost of a compound index can be influenced by the order of the columns in the index definition. When defining a compound index, it’s generally recommended to list the most selective column first, followed by the second most selective column, and so on. This can help PostgreSQL to more efficiently filter the index based on the most selective conditions first, before filtering further based on less selective conditions.
Overall, the cost of a compound index can be relatively high compared to a single-column index, especially if the table is large and the index includes multiple columns with low selectivity. However, in many cases, the performance benefits of a compound index can outweigh the cost, especially for queries that frequently involve multiple conditions that are frequently used together.
More info: how to optimize Compound indexes in PostgreSQL
To optimize the compound index, you may want to consider the order of the indexed columns. In general, you should order the columns in the index based on their selectivity and the order of the search conditions in the query. In this example, `customer_id` has higher selectivity than `order_date`, so it should be listed first in the index.
You may also want to consider the size of the indexed columns and the overall size of the index. In general, you should avoid creating excessively large indexes, as they can slow down insert, update, and delete operations on the table.
To further optimize the query performance, you may want to consider other indexing methods, such as GiST or BRIN, depending on the specific characteristics of the data being indexed. Additionally, you may want to consider optimizing the query itself, such as by using a covering index or by rewriting the query to use a more efficient join strategy.
Creating a compound index on multiple columns can significantly improve the performance of SQL queries that involve multiple search criteria, but it’s important to carefully consider the characteristics of the data and the specific query patterns before creating indexes.
So, compound indexes in PostgreSQL can be a useful tool for optimizing the performance of queries that filter or sort on multiple columns. When creating a compound index, it’s important to consider the order of the columns in the index to ensure optimal performance.
Several things to consider to ensure that it provides the best performance benefits when using a compound index in PostgreSQL:
1. Selectivity of columns: It’s important to consider the selectivity of the columns included in the index. Selectivity refers to the number of distinct values in a column relative to the total number of rows in the table. Columns with high selectivity are more useful for indexing, as they can help to quickly filter the index to a small subset of rows.
2. Column order: The order in which the columns are listed in the compound index definition can have an impact on query performance. It’s generally recommended to list the most selective columns first, followed by less selective columns.
3. Data distribution: The distribution of data in the table can also affect the performance of a compound index. If the values in the indexed columns are highly skewed or have many null values, the index may be less effective at filtering rows.
4. Index size: Compound indexes can be larger in size than single-column indexes, as they store data for multiple columns. This can increase the disk space required to store the index and may affect the speed of index scans.
5. Maintenance overhead: Compound indexes require additional maintenance overhead compared to single-column indexes. Whenever the underlying table is updated, the index must be updated as well.
By considering these factors and designing the compound index carefully, it’s possible to create an index that provides the best performance benefits for a given set of queries. However, it’s important to note that the optimal index design can vary depending on the specific use case and the distribution of data in the table, so it’s important to carefully evaluate the effectiveness of any index design through benchmarking and testing.
REF
https://www.pgmustard.com/blog/indexing-best-practices-postgresql
Bài viết khác
PostgreSQL : subquery, CTE
What is subquery in PostgreSQL? In PostgreSQL, a subquery is a query that is nested inside another query. The subquery is executed first, and its results are used as input to the outer query. Subqueries can be used in various contexts, such as in the SELECT, WHERE, and HAVING clauses of a query. For example, […]
Optimize SQL : rule and todo list
Some rule and todo list to Optimize SQL REF https://www.pgmustard.com/blog/indexing-best-practices-postgresql
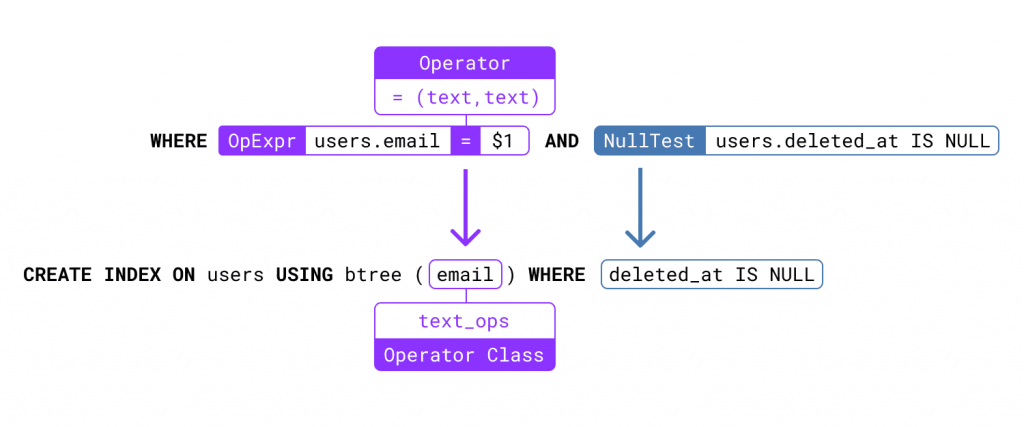
PostgreSQL indexing best practices
Don’t index every column If indexes are so useful, why don’t we add them to every column? There are a few good reasons, but a big one is that indexes add overhead to writes. Not only do indexes need to be kept up to date when we write to the table, but they can also […]



 Khoá học lập trình game con rắn cho trẻ em
Khoá học lập trình game con rắn cho trẻ em 




