If you are trying to build a system and try to scale it globally, sell your product all over the world, you will need a collection of rules that are implemented in design and code.
In this article, we will make clear some basic knowledge on how to build an system able to scale globally
First, let ‘s take a look at is a diagram of how our application looks:
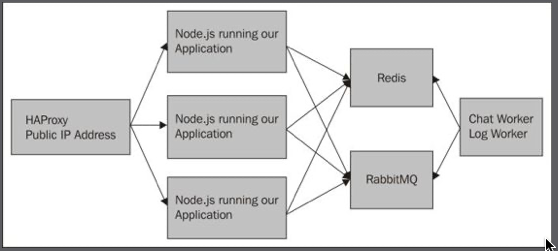
The front public-facing address of our site will be the server that is running HAProxy. In this setup, we will only want one server running HAProxy, and if it is production, this site should have a static IP and a public DNS record. HAProxy is very efficient at load balancing, and one of them can handle a lot of traffic.
Eventually, we can run two behind a balanced DNS record
HAProxy will then send the requests to one of our application servers behind it. These servers do not need a public-facing DNS record. They only need to communicate with the HAProxy server (and technically our computer so that SSH/Ansible will work). Each one of these servers will only be running one instance of Node and our application. We could even configure Ansible to kick off multiple instances of Node.
Node.js is single-threaded, so most computers should be able to easily handle Node.js running once for each core. We will only need to update our start script and the HAProxy config to do this.
Each Node.js instance will create a connection to Redis. This is important as it keeps state out of the application layer. Redis is the only server that has complete knowledge of who is logged in (through connect sessions) and what rooms and messages exist (our application). Our application layer just takes a request, asks Redis what’s going on, and returns a response. This high-level view is true if Node.js or Socket.io serves the response. If the session only lived in the memory on one machine, then when another machine responded to the request, the machine would not know that the user was logged in.
RabbitMQ is used for logging. Exactly like Redis, each application server creates its own connection. I will admit that this is not a great example of RabbitMQ’s abilities. We can consider an example though.
Our example uses RabbitMQ for e-mails. Currently, our application does not send any out. E-mails can be resource-intensive. This does not mean that it will take up a lot of CPU cycles, but rather it relies on another server to respond. If we sent an e-mail during an HTTP response, a timeout could cause our application to appear slow and unresponsive. Let’s say that we want to send out an e-mail when someone first signs up and when someone sends a direct chat (a feature we don’t currently have). The first thing to do is create a worker that will watch an e-mail queue, which we create in RabbitMQ. Then, we will create a code that will easily add a message to this queue. This would be similar to our logging code. Each layer would only worry about what it was designed to do. We also could quickly change our e-mail processor. We just stop the e-mail worker and run our deploy script for the worker.
This brings us to the last layer of our application, workers. The setup for these is very similar to that of the application layer, Node.js, start and stop scripts. The difference is that the workers respond to RabbitMQ queues or a time interval.
Two way to scale: vertical and/ or horizontal , or scale by quality / quantity
There are two different types of scaling, horizontal and vertical. We will discuss which applies to our application layers.
Scale Horizontal
Horizontal scaling involves adding more servers to respond. This method is harder to implement, but it can scale indefinitely. Our layer with Node.js web servers scales horizontally. If we notice that our application is timing out or is slow, we can spin up more instances to handle the load.
Horizontal scaling requires that no application state be stored on the server. This makes sense because we can never be sure if the same server will respond to requests.
The worker layer also can scale horizontally. If the workers cannot keep up, then we can create more workers.”
Scale Vertical
Vertical is the simplest way to scale. The downside to this is that it has a finite limit. If we use AWS as our provider, we can only currently create instances up to a certain number of CPUs and GBs of RAM (24 TB RAM currently). It involves giving more resources to a server. In our build HAProxy, Redis and RabbitMQ can all scale vertically. If we run out of memory for Redis, then we can use a larger instance to run Redis. With the current maximum resources that AWS has, we should not run into a ceiling until we have a very, very large site.
How about database to build for global scale
We use distributed database
Or a system with master database and many slave
Other Content build for global scale
You can keep a track on this serial : Build for global scale here
https://tranhuy.bachkhoasaigon.com/tag/build-for-global-scale
Keywords
handle hundreds of thousands (or more) of simultaneous workloads
adding more instances of the application
rolling upgrades,
elastic horizontally scalable architecture,
geographic distribution
Distributed database
Database replication
Reference
https://aws.amazon.com/ec2/instance-types/high-memory/#:~:text=Amazon%20EC2%20High%20Memory%20instances%20have%20the%20highest%20amount%20of,memory%20databases%20like%20SAP%20HANA.
Bài viết khác
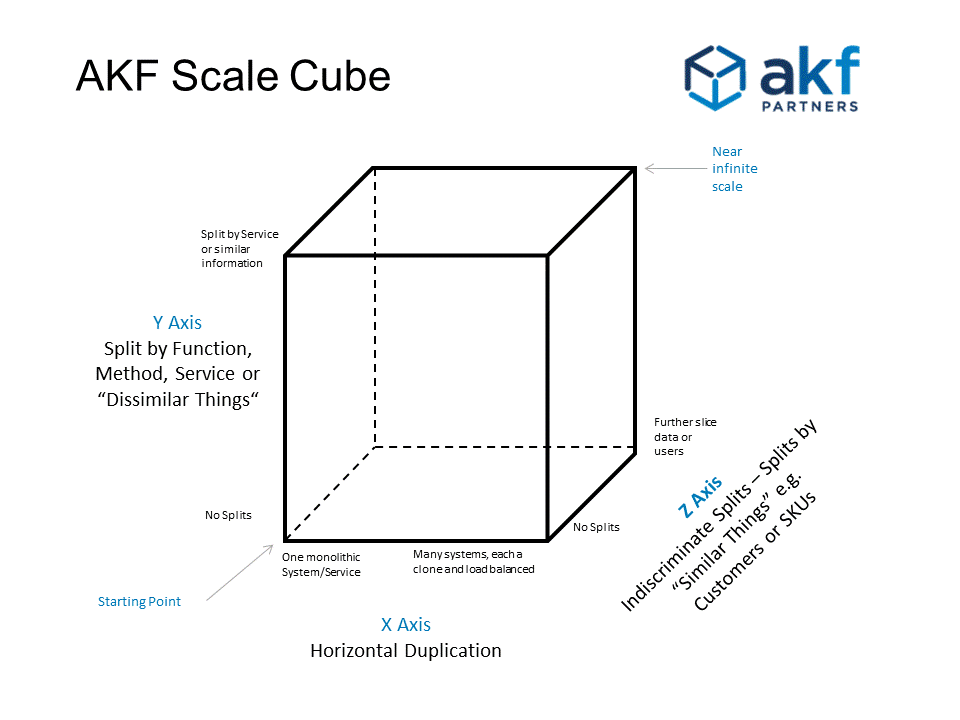
Build for global scale: AFK scale cube and basic rule to build an application for global scale
REF https://akfpartners.com/growth-blog/scale-cube
PostgreSQL : subquery, CTE
What is subquery in PostgreSQL? In PostgreSQL, a subquery is a query that is nested inside another query. The subquery is executed first, and its results are used as input to the outer query. Subqueries can be used in various contexts, such as in the SELECT, WHERE, and HAVING clauses of a query. For example, […]
Optimize SQL : rule and todo list
Some rule and todo list to Optimize SQL REF https://www.pgmustard.com/blog/indexing-best-practices-postgresql

PostgreSQL Compound indexes
What is Compound indexes in PostgreSQL? A compound index (also known as a composite index or a multi-column index) refers to an index that is created on two or more columns of a table. It allows PostgreSQL to quickly find rows that match a query condition based on the values in multiple columns, which can […]
Use AWS to deploy your applications and services
Amazon Web Services (AWS) is a cloud computing platform that provides a wide range of services to help businesses and individuals build and deploy applications in the cloud. AWS offers a variety of services such as compute, storage, databases, networking, security, and more. In this guide, we will walk through the steps to get started […]
Use docker to run go project
Docker is a powerful tool that enables developers to create, deploy and run applications in a containerized environment. Using Docker to run Go projects has many advantages, including the ability to isolate your application from the underlying operating system, simplifying the deployment process, and allowing for greater scalability and flexibility. In this guide, we will […]
 Khoá học lập trình game con rắn cho trẻ em
Khoá học lập trình game con rắn cho trẻ em 




